Skip Scan
How Phoenix Skip Scan uses key-range hints to efficiently skip non-matching row-key regions.
Phoenix uses Skip Scan for intra-row scanning which allows for significant performance improvement over Range Scan when rows are retrieved based on a given set of keys.
Skip Scan leverages SEEK_NEXT_USING_HINT in HBase filters. It stores information about which key sets or key ranges are being searched for in each column. During filter evaluation, it checks whether a key is in one of the valid combinations or ranges. If not, it computes the next highest key to jump to.
Input to SkipScanFilter is a List<List<KeyRange>> where the top-level list represents each row-key column (that is, each primary key part), and the inner list represents OR-ed byte-array boundaries.
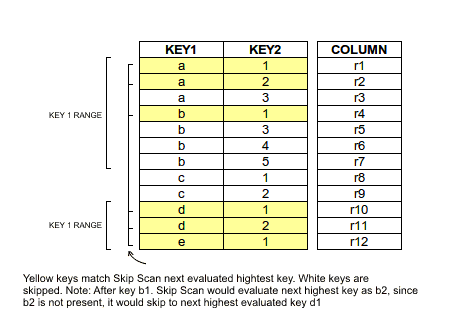
Consider the following query:
SELECT * FROM T
WHERE ((KEY1 >='a' AND KEY1 <= 'b') OR (KEY1 > 'c' AND KEY1 <= 'e'))
AND KEY2 IN (1, 2)For the query above, the List<List<KeyRange>> passed to SkipScanFilter would look like:
[[[a - b], [d - e]], [1, 2]]Here, [[a - b], [d - e]] represents ranges for KEY1, and [1, 2] represents the keys for KEY2.
The following diagram illustrates graphically how the skip scan is able to jump around the key space: